# Data Processing Pipeline
# Overview
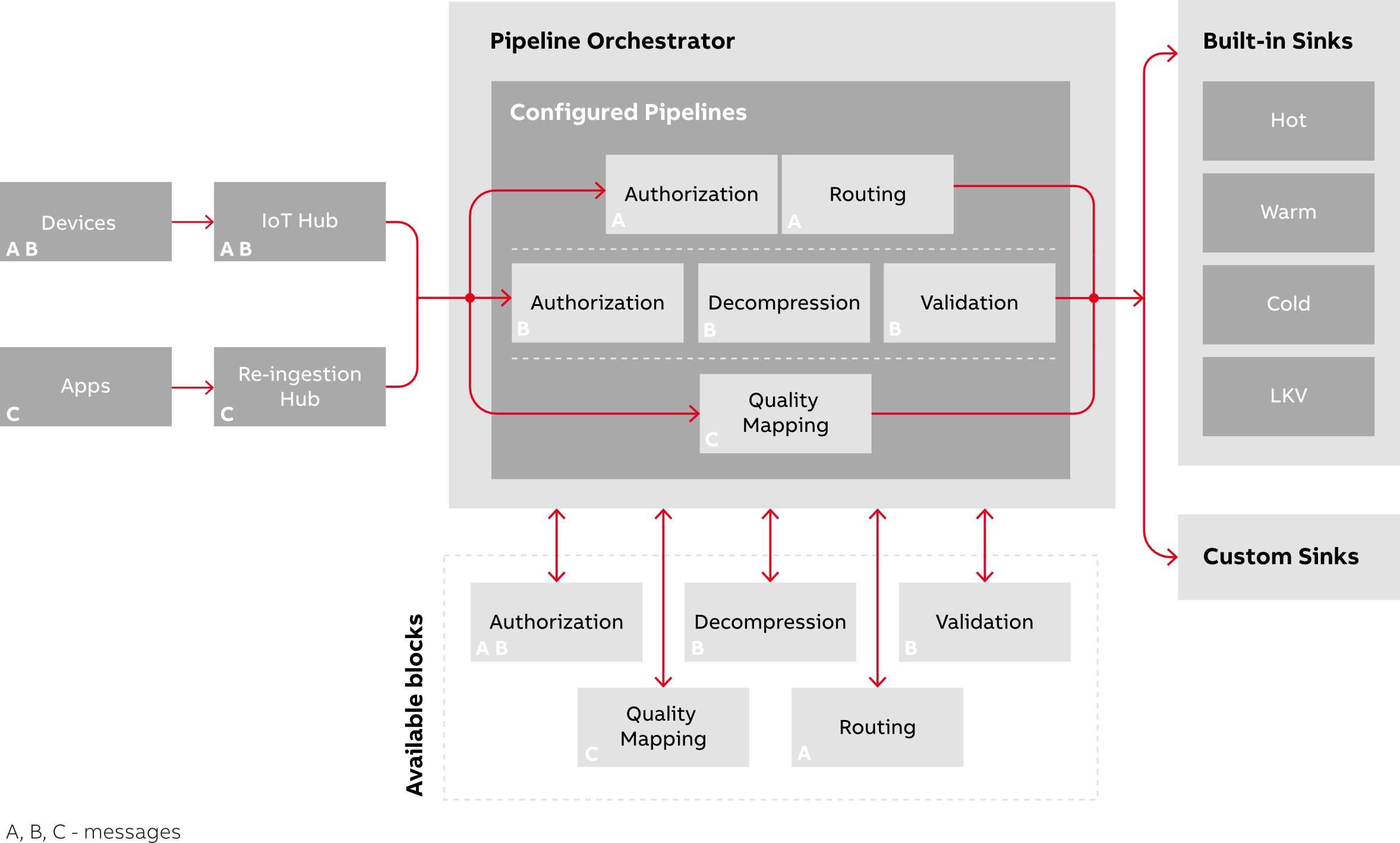
Messages entering the DPP from the IoT hub are redirected to the authorization, decompression, validation pipeline(s), or quality mapping depending on the message headers attached to the incoming message. Processed messages are then published to the telemetry event hub before forwarding to TSI.
Following is a high-level overview of how processing logic affects data flow in the DPP.
# Decompression
The Ability Platform's Data Processing Pipeline supports two kinds of decompression algorithms out of the box: gzip and deflate. Each algorithm is available through a dedicated step. To force a message to go through a decompression procedure, you need to configure routing correctly.
# Compression headers
By default, the Data Processing Pipeline comes with a setup, where each
IoT Hub message decorated with either ability-compression or compression header is routed correctly
to the required step. However, this header is not mandatory. It is up to the
Client, and a matter of request to the Operations team, to update this header
and use any other indicator of the compressed message.
Warning
It is important to put the decompression step within the
eventSteps section of the routing configuration. That section indicates steps,
which operate on the whole IoT Hub message.
# Data Validation
The data processing pipeline (DPP) of the Ability Platform features data validation and data authorization functionality.
Data validation is executed with the help of InfoModel and TDR APIs and is integral to the Ability platform. Validation is performed by default, requiring no action on the part of a BL user. Validation and/or decompression steps may be disabled by an authorized admin with the DPP configuration API.
# Validation Logic
DPP validation logic is applied to all incoming telemetry messages to ensure that they contain all the required references and headers, and are properly formatted. For more information on validation rules, see the Device Created event page.
For messages to work successfully with DPP validation logic, ensure that messages meet the following criteria.
The required message headers are present and have valid values.
Headers Validation
The DPP checks the presence of the following headers:
"ability-messagetype" or "msgType" are set by the device. Depending on whether API V1 or V2 is used, the following headers are required:
V1 API message headers:
ability-messagetype='timeSeries' ability-messagetype='alarm' ability-messagetype='event'
V2 API message headers:
msgType='variable' msgType='alarm' msgType='event'
For the ingestion path, the DPP also checks the following headers:
required "iothub-connection-device-id" (set by IoT Hub based on connected device Id).
required "iothub-connection-auth-method" (set by IoT Hub based on selected method of authentication to IoT Hub, for devices in platform it is X509).
For the re-ingestion path, the DPP also checks the following headers:
- required "x-opt-publisher" (set to publisher Id when using the Event Hub publish API)
The payload is a valid JSON code block. This JSON code block must be compliant with accepted JSON formatting based on the message type. For more information on proper formatting, see the Payload Schema with Edge Devices.
JSON Validation
The DPP verifies that the event payload conforms to one of the JSON schemas, connected with the following particular message types:
The variable in the payload exists in the type definition of the object model.
Object Model Validation
The DPP calls the InfoModel API endpoint:
https://{infoModelService}/v1/objects/{objectId}/models/{model}If a response with an existing object model is received, validation is successful.
The variable is compliant with its definition (data type and the validation rules based on keywords). The variable may be obtained by requesting the type definition referenced by the object model.
Type Definition Validation
Variable/TimeSeries:
The DPP calls the TDR API endpoint:
https://{tdr}/v1/modelDefintions/{model}/types/{typeId}/versions/{version}?isHolistic=trueWhen the TDR response indicates a non-existing type definition, validation fails.
When the TDR indicates an extensible type, additional variables are collected using the InfoModel extensions endpoint:
https://{im}/api/v1.0/objects/{objectId}/models/{model}/extension.When a specified variable does not exist in the type defintion, validation fails.
When a specified variable exists in the type defintion, the DPP executes a set of validation rules depending on the type of variable:
string variable: Types must match.
boolean variable: Types must match.
numeric variable: Types must match. constraints. If the TDR type definition indicates an enum type, the value of the variable must match the enum definition.
Alarms:
The DPP calls the TDR API endpoint:
https://{tdr}/v1/modelDefintions/{model}/types/{typeId}/versions/{version}?isHolistic=true- When the TDR response indicates a non-existing type definition, validation does not fail to maintain backward compatibility.
- When a type definition for incoming telemetry exists, but there is no matching alarm definition, validation does not fail to maintain backward compatibility.
- When a type definition for incoming telemetry exists and there is a matching alarm definition name, validation fails if the incoming data type is different than the one in the TDR alarm definition.
Events:
The DPP calls the TDR API endpoint:
https://{tdr}/v1/modelDefintions/{model}/types/{typeId}/versions/{version}?isHolistic=true- When the TDR response indicates non-existing type definition, validation does not fail to maintain backward compatibility.
- When a type definition for incoming telemetry exists, but there is no matching event definition, validation does not fail to maintain backward compatibility.
- When a type definition for incoming telemetry exists and there is a matching event definition name, validation fails if the incoming data type is different than the one in the TDR event definition.
# Quality Mapping
The Data Processing pipeline includes a step, which executes a process of splitting telemetry data quality integer into logical parts to make them accessible from the Data Access API. This transformation of extracting logical parts of "quality data" from the 32-bit number will be called "quality mapping" further in this document. The new data quality step usage depends on the platform configuration, and the feature is disabled by default. The Client needs to opt-in by submitting a request to the Operations Team.
# Output models
The Data Processing pipeline introduces support for two types of quality mappings: OPC-UA and IEC-62361-2.
An example of a telemetry data model:
{
// Identifier for object
"objectId": "2B129E4C-0944-4534-8E8B-DEB49D8AF0AC",
// model that scopes the variable
"model": "abb.somedomain.somemodel",
// data source variable
"variable": "SomeVariableName",
// timestamp of the reported value
"timestamp": "2018-05-217T23:00:00Z",
// reported value, e.g. 42
"value": 42,
//which is 0x40000082 or 0100 000 000 000 000 000 1000 0010
"quality" : 1073741954
}
An example of an output model:
{
// Identifier for object
"objectId": "2B129E4C-0944-4534-8E8B-DEB49D8AF0AC",
// model that scopes the variable
"model": "abb.somedomain.somemodel",
// data source variable
"variable": "SomeVariableName",
// timestamp of the reported value
"timestamp": "2018-05-217T23:00:00Z",
// reported value, e.g. 42
"value": 42,
//which is 0x40000082 or 0100 000 000 000 000 000 1000 0010
"quality" : 1073741954,
"qualityFlags" : {
"validity" : "uncertain",
"limit" : "low",
"historian" : "interpolated"
}
}
Common properties of an output quality mapping model:
qualityFlags.validity
qualityFlags.protocol
qualityFlags.limit
qualityFlags.historian.origin
qualityFlags.historian.isPartial
qualityFlags.historian.isExtraData
qualityFlags.historian.isMultipleValue
qualityFlags.isOverflow
OPC UA:
qualityFlags.subCode
qualityFlags.structureChanged
qualityFlags.semanticsChanged
qualityFlags.infoType
IEC 62361-2:
qualityFlags.timestampInfo
qualityFlags.additionalInfo
qualityFlags.dataQuality
qualityFlags.errors
# Information model data quality hint
The default quality mapping can be defined in any Model Definition as an additional top-level attribute. This will serve as a default setting for all Type Definitions that are defined for this Model Definition:
{
"modelId": "modelId1"
"qualityMapping": "OPC UA"
}
Additionally, each Type Definition may define the quality mapping attribute, which would override the setting in its Model Definition:
{
"typeId": "<type>",
"version": "1.0.0",
"model": "modelId1",
"qualityMapping": "IEC62361-2",
"properties": { *** }
}
When both the Model Definition and the Type Definition have the attribute set, the Type Definition will be prioritized.
# Quality validation rules
By default, the process of data quality transformation attempts to apply one of the two available mappings.
If there is an existing mapping hint in the Information Model and the quality value of incoming telemetry cannot be processed using that mapping, an error message is logged, and the telemetry message processing is interrupted.
If there is no existing mapping hint in the Information Model and the quality value of incoming telemetry cannot be processed using any of the supported mappings, telemetry data is forwarded to storages without quality flags model.
# Telemetry Data Routing
Data Routing functionality allows for redirecting incoming telemetry data based on defined filters into one of four targets, which come as part of the standard platform delivery. These are Hot, Warm, Cold, and Last Known Value (LKV) target Event Hubs, which are consumed by appropriate storage mechanisms. The client may opt into using all four, only selected ones or none at all.
It is also possible to define custom targets (sinks) to which selected telemetry data should be published.
As presented in the diagram at the beginning of the article, Routing Decoration is responsible for executing the routing flow as configured.
Lost telemetry data
Telemetry data, which does not match any of the defined filters, is not propagated to any of the sinks. Therefore, such telemetry is not stored or processed by any of the downstream components and cannot be restored or reprocessed again.
# Routing configuration
Routing configuration allows for defining telemetry data item routing paths based on the characteristics of each message (headers content, body properties). The content of the headers and property values (also for dynamic, nested JSON objects) can be used in routing definitions using the standard Query Expression Language syntax.
Changing the routing
The configuration of the routing is done as shown in the example below. However, the actual change may only be applied by the Operations Team at the client's request.
# Routing configuration example
{
"rules": [
{
"name": "variables_routes",
"filters": [
{
"sinkName": "hot",
"filter": "msgType = 'variable'"
},
{
"sinkName": "cold",
"filter": "msgType = 'variable'"
}
]
},
{
"name": "alarms_routes",
"filters": [
{
"sinkName": "hot",
"filter": "msgType = 'alarm'"
},
{
"sinkName": "warm",
"filter": "msgType = 'alarm' AND tenantId IN ['8bed9955-b86b-4fad-baf1-fd8b327f2070', '3efd3e60-5171-42de-9bec-d48d56efe8dd']"
},
{
"sinkName": "cold",
"filter": "msgType = 'alarm'"
},
{
"sinkName": "customSink1",
"filter": "msgType = 'alarm' AND objectId in ['8bed9955-b86b-4fbd-baf1-fd8b327f2070', '4efd3e60-5171-42de-9bec-d48d56efe8dd']"
},
{
"sinkName": "customSink2",
"filter": "msgType = 'alarm'"
}
]
},
{
"name": "debugging_routes",
"filters": [
{
"sinkName": "hot",
"filter": "objectId in ['8bed9955-b86b-4fbd-baf1-fd8b327f2070', '4efd3e60-5171-42de-9bec-d48d56efe8dd']"
},
{
"sinkName": "customSink2",
"filter": "tenantId = '8bed9955-b86b-4fad-baf1-fd8b327f2070'"
}
]
}
],
"customSinks": [
{
"name": "customSink1",
"type": "EventHub"
},
{
"name": "customSink2",
"type": "EventHub"
}
]
}
# Configuration sections
There are two major sections in the configuration:
rules
This section defines the way telemetry data should be routed. With the usage of filter properties, the client may re-direct messages between a set of Ability Platform built-in sinks (Hot, Warm, Cold, and Last Known Value), as well as define routes to the client's customSinks.
customSinks
This section may be used to specify a custom target where telemetry data should be routed. The named sink may later be used within the rules section to define filters. Currently, only the Event Hub custom sink is supported.
Adding custom sinks
SAS Tokens for corresponding custom sinks are kept in Key Vault. Adding a custom sink to routing configuration should be executed in the following way:
- add an entry to Key Vault with SAS token, the entry should follow naming
convention
TelemetryDataRouter_Sink_{sink_name}, - add an entry to the
customSinkssection in routing configuration.
# Special handling for non-validated data
Telemetry Routing configuration provides four built-in sinks: hot, warm, cold, and last known value. As these are delivered by the platform itself, you cannot change their connection strings, but you can freely arrange the routing configuration to use them in the most effective way for your use cases.
However, built-in sinks accept only validated data, which are telemetry items that went through the Ability validation logic. Telemetry data is only forwarded to defined custom sinks if the validation logic in DPP configuration is disabled.
Telemetry is sent to all sinks
Custom sinks accept any data. If a telemetry item does not match any of the sinks and routing fallback is active, telemetry will be sent to all built-in sinks.
# Message Error Handling
Message errors may be generated at any point during message processing. Errors (i.e. corrupted data) may be divided into three major categories:
Rejected messages - when processing fails due to expected circumstances (such as unauthorized telemetry or failed validation) or temporarily occurring problems (rolling update and JSON schema update).
Infrastructure exceptions - when processing fails due to temporarily unavailable services (e.g. AuthZ for authorization or TDR for validation).
Unhandled exceptions - when processing fails due to bugs.
Information about data processing errors (body of event plus failure reason) is stored in Azure Storage Blob Containers. This allows an Admin or Operations Team member to debug problems with corrupted data or devices in a corrupted state following generation of the event. This feature is turned on by default.
A discussion of the three categories of errors follows.
# Rejected Messages
Rejected messages are messages that are non-compliant with validation rules or that were sent by an unauthorized party (device or re-ingestion publisher). The incoming message is properly formed, with no errors in the code. However, the message is not formatted to comply with DPP validation rules. In the absence of validation rules, the message would be processed properly.
Handling is configurable.
When "discard" mode is selected, a warning is logged in Application Insights with the reason for the failure. Used for debugging.
When "store" mode is selected, the error is stored, along with a reason for the failure and exception details. The whole event is stored in the Azure Storage queue for further processing. The storage location is also a part of the configuration.
Example
A telemetry message enters the DPP as a properly formed JSON, however the message does not comply with the defined number of JSON object ID properties supported by the DPP.
# Infrastructure Exceptions
Infrastructure exceptions are messages that cannot be processed due to the unavailability of one or more components within the DPP. The incoming message is properly formed, with no errors in the code.
The message is already handled but cannot proceed.
The DPP will restart the ingestion service and all messages in the message batch entering from the IoT hub will be reprocessed at the point of ingestion, not at the checkpoint where a batch failed.
Example
The DPP receives a telemetry message from the IoT hub where it awaits forwarding to the event hub. However, the event hub is unavailable due to, e.g. a networking issue, MS update, etc.
# Unhandled Exceptions
Unhandled exceptions are messages that fail due to an asymmetry between the code recognized by the DPP and the code used in the incoming message. The incoming message may be properly formed and technically contain no errors. However, because the code expected by the DPP differs from the code used in the message, the message cannot be processed.
Handling is configurable.
When "discard" mode is selected, an error is logged in Application Insights with the reason for the failure, along with exceptions details. Used for debugging.
When "store" mode is selected, the error is stored, along with a reason for the failure and exception details. The whole event is stored in the Azure Storage queue for further processing. The storage location is also a part of the configuration.
Unprocessed messages are redirected to the (re)ingestion errors queue for further analyzing by the operations team.
Example
An incoming message contains a type decimal in a particular value, but because the DPP expects a type integer, the message fails. In this case the processing algorithm cannot translate between a decimal and an integer.
# Configuration
The behaviour described in this document is the default configuration of DPP. There is a possibility to change the defaults if your project requires that. In such case, you should create a ticket for the Operations Team explaining what you want to change and why.
The possible modifications include:
- skipping some steps from the pipeline;
- changing the behaviour of some steps for different kinds of telemetry (i.e. enable "quality" tag only for variables);
- changing the way how compression works;
- handling messages with custom headers differently;
- etc...
Feel free to reach out to the Client Success Team (CST) for help with defining your requirements and to check if DPP supports your case.