# Performance
The ABB Ability™ Platform can be scaled to support various types of configurations. Underlying components of the ABB Ability™ Platform do not provide unlimited capacity. Key parameters have been extracted to provide configuration of, storage of, and access to device data. The three critical areas are:
- Steady state bandwidth created by IoT devices or Edge nodes.
- Planned access to collected IoT data.
- Configuration actions on the environment.
Each of these areas interact with each other. Improper scaling of any one component of the ABB Ability™ system for the planned loading can adversely affect the entire environment. The following sections will identify key configuration parameters as they relate to the planned usage of the ABB Ability™ Platform.
# Simplified View of the ABB Ability™ Platform
In its simplest form, the ABB Ability™ Platform can define IoT devices that have properties, and can generate telemetry, alarms, events, and files, which are stored in the cloud. Once stored, these be accessed with various cloud APIs for analysis. Additionally, a re-ingestion interface is provided, and files can also be uploaded from the Data Access API. Three basic subsystems are in play to achieve this.
# Storage Subsystem Input
The ABB Ability™ Platform has three primary storage mechanisms for the different types of device-generated data. Each storage mechanism has different performance and scaling options.
- Telemetry, alarms and events are stored in Time Series Insights (TSI) and Azure blob storage. This data typically comes from Devices, that is Edge nodes, but a re-ingestion interface is also available.
- Files are stored in Azure blob storage. Devices and Edge nodes can pass files through the IoT Hub or DataAccess can be used to store files.
- Device properties are stored in Cosmos DB. Devices can optionally update their own properties.
The following picture represents the key parameters to extract from any implementation proposal.
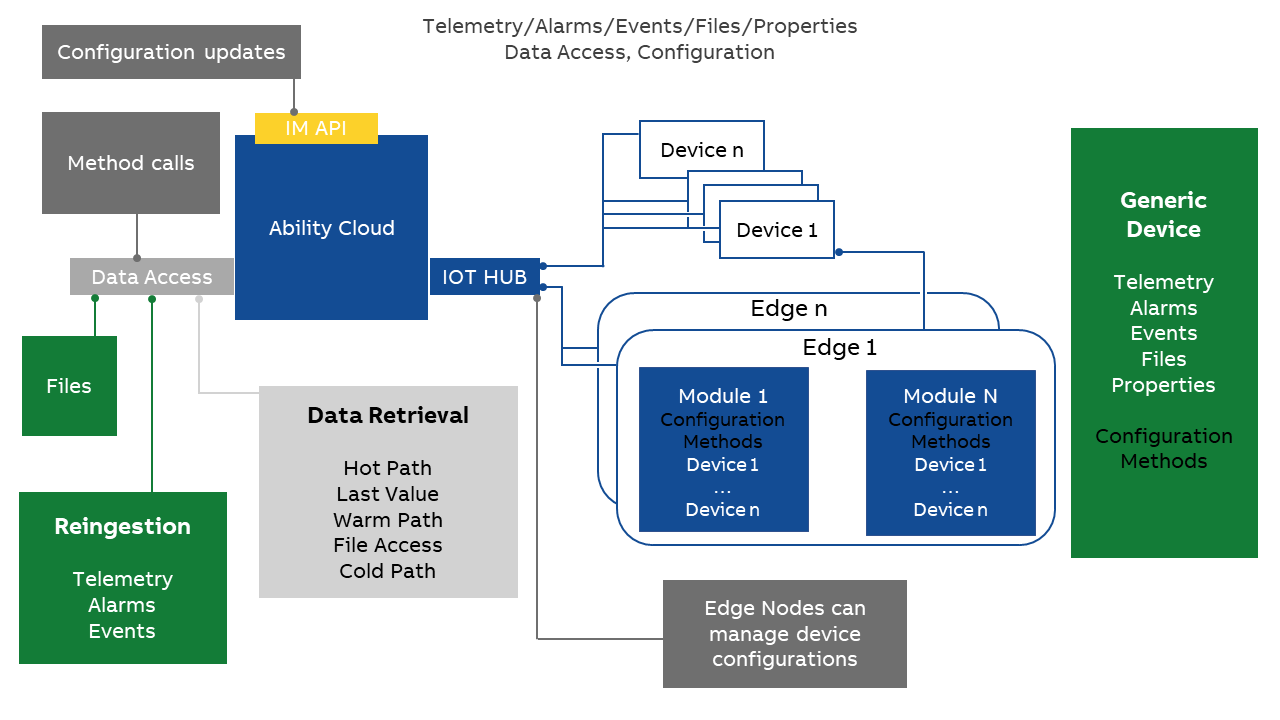
# Telemetry, Alarms, and Events
This release currently supports three tiers of ingress. Once you determine the average sustained bandwidth for the current and future devices, the correct SKU for Time Series Insights can be selected to provide the resources required to match the desired application.
| TSI SKU | Maximum Ingress | Maxium Bandwidth | Event Bursts |
|---|---|---|---|
| S1 | 120/s | 120KB/s | 2x maximum for less than 1 hour |
| S2 | 1200/s | 1200KB/s | 2x maximum for less than 1 hour |
| P1 | based on bandwidth | 6MB/s | 12MB/s |
TSI S1 and S2 round up telemetry to the nearest kilobyte. If your data is 1KB or less, you can achieve 120/s with S1 and 1200/s with S2. However, if the TSI event is 1025 bytes, your ingress frequency will be cut in half, S1 will be reduced to 60/s, and S2 to 600/s. The larger TSI event will trigger the bandwidth limit for S1 and S2.
TSI P1 is based strictly on bandwidth. You can mix and match large and small data as long as you stay under the 6MB/s steady state. From a cost point of view, the entry price of P1 is equal to 6 UNITs of S2. We recommend P1 if your application will ever exceed 720/s or 750KB/s.
The current Hot Path functionality can only process 1MB/s (6000/s of basic telemetry). This mechanism will be updated in a planned update that will allow the platform to accept an overall higher ingress rate. Once the functionality is updated, appropriate documentation will reflect the updated limits.
# Retrieval Subsystem
The retrieval subsystem provides mechanisms to extract all the data generated by IoT devices, file uploads, and re-ingestion. This subsystem is expected to scale accordingly to meet any retrieval demands. The key components are:
- Last Value
- Hot Path
- Warm Path
- Cold Path
- File download
The Data Access API handles everything except Cold Path data retrieval.
# Last Value and Hot Path
Last Value and Hot Path are defined by latency. Latency is the duration of time between generating a value at the device, and delivering it to the client via a hot path subscription, or writing and retrieving with a last value request. For last value, data is stored in an Azure REDIS cache. Latency in both cases should be minimal, that is, less than one second in many cases. However, since both depend on the network topology between the client and the ABB Ability™ Data Access API, delays can be longer.
Performance of these two features also depends on the path from the device or Edge to the cloud, plus any processing time. In the steady state, latency should be minimal. However, if there is a burst of traffic from any devices or another burst to other parts of the ABB Ability™ Platform, this can also introduce additional latency. These delays can be minimized by properly scaling components to level that and match end-user performance requirements.
# Warm Path
Warm Path data availability is defined by and SLA by Microsoft. For a properly scaled TSI component, TSI will have data available within 60 seconds. This will be true as long as the data process can get the data to the ingress side of TSI in a timely manner. Similar to Hot Path and Last Value, the same processing delays can affect Warm Path Data availablity. Additionally, TSI will throttle if ingress exceeds the current SKU/UNITs configuration.
# Cold Path
Cold Path is just storing the variable/alarms/events in JSON files in Azure Blob Storage. As long as Cold Path can keep up with ingress, data will be current. As with the other types of data access, if there are processing delays, the latest values will not be available immediately.
# File Download
File downloads are limited by the bandwidth of the connection to the ABB Ability™ Platform.
# Configuration Subsystem
The configuration subsystem supports the entire ABB Ability™ Platform. Major components include the Principle Manager, Type Definition Registry and Information Model Service. Both the Storage and Retrieval subsystems depend on the Configuration subsystem to function.
- Data Processing Pipeline uses all three to verify device permission and data formats before storing data
- Data Access uses all these to validate tokens and improve query efficiency.
As with Data access, this subsystem is expected to scale as needed to support both internal loading triggered by the storage subsystem, property updates triggered from devices, and external loading triggered by Data Access.
Additionally, configuration changes can push model updates and send methods to devices. While many of these actions seem trival from the cloud APIs, they can result in a burst of messages to all devices. When using this funtionality, user applications must be aware of the impact on the system. Information is available to identify the best practices to ensure model updates and commands are executed in a timely manner.
# Summary
The overall cost of an environment will be determined by the design picked. After a design is selected that defines the planned storage bandwidth and warm path data retention, this information can be used to provide a cost estimate.